前言:
一直想研究研究如何生成词云,今天抽点时间给大家分享一下制作词云的过程,本文重在研究词云如何制作,由于时间仓促,至于爬取的数据量不大,大家可自行爬取其他数据。
python爬取爱情公寓电影评论并制作词云
爬取爱情公寓电影评论
因为主要是练习词云,所有我就顺便百度了一下爱情公寓,就出来了,链接如下:http://v.baidu.com/movie/134804.htm?fr=open_bdps_dyyg,大家可自行换其他网站爬取评论,数据量最好大一点,才有价值。也可以当一个爬虫进行练习,里面也还是有一些坑的,我们直接进去网站,到下直接就看到评论了,总共只有240条,我们按照常规套路右键检查,直接选取元素,点选评论,
这里写图片描述
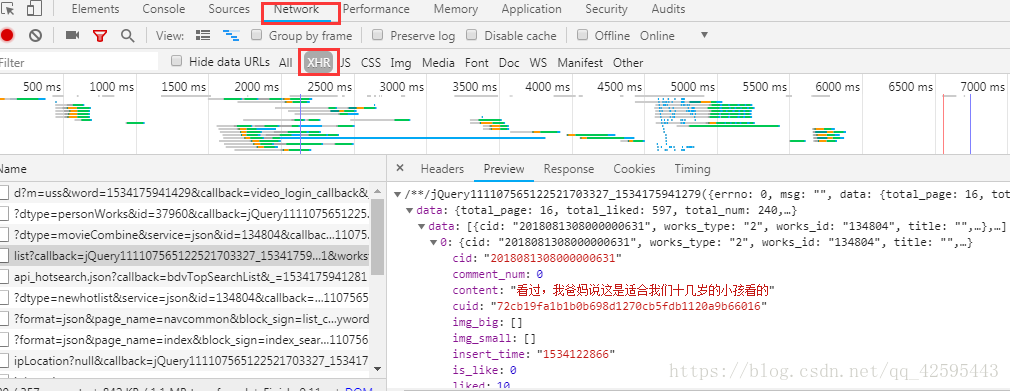
直接看到结果了,然后一如既往的把上面的url拿下来,直接一波requests.get请求,结果一看源代码,根本就没有任何关于评论的数据。这样我们就怀疑是不是ajxs动态加载的,我们选到network,再选到xhr中,仔细观察,会发现评论数据藏在一个list开头的js文件中,
这里写图片描述
再点到hesder回去看一下,url其实并不上上面的那个,还是发送的get请求,这样就好办了,我们直接在js文件中提取comment数据就行了,直接上代码:
1
2
3
4
5
6
7
8
9
10
11
| def get_page(self, url):
response = requests.get(url, headers=self.headers)
response.encoding = "utf-8"
# 注意下面两行代码在处理过程中容易多去花括号或者少去花括号,都会造成json格式报错,一定要注意
data = response.text.split('(', 1)[1] # 根据(进行切片一次处理,取第二部分
data = data[0:len(data) - 1] # 然后去掉后面的)和;
items = json.loads(data)
for i in range(len(items['data']['data'])):
item = items['data']['data'][i]['content']
# print(item)
self.info_list.append(item)
|
在这里面要注意一下几点:
- 我们获取的网页源代码,其实不是标准的网页源代码,前面会有一些多余的‘fetchJSON_comment98vv56725(’;这样的。
- 后面也会多余一个,
- 我们再去掉这些多余的符号的时候,一定要小心,千万不要多去,或者少去,都会导致后面的json数据提取不出来。(这里推荐大家把源代码复制下来,然后用json格式在线解析,就一目了然了。)
1
| items = json.loads(data)
|
json.loads 是将字符串格式转化为json数据。
1
| for i in range(len(items['data']['data'])):
|
len(items[‘data’][‘data’])是用来动态计算每一页有多少个评论。
这里结果我用了一个列表把数据装了起来,在调一个写入的方法将数据写入到本地TXT文件就行了。代码如下:
1
2
3
4
| def write(self, info):
with open('comment.txt', 'a', encoding="utf-8") as f:
f.write(info + "\n")
f.close()
|
最后代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| import requests
import json
import jieba
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
class Aiqing(object):
def __init__(self):
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
self.info_list = []
def get_page(self, url):
response = requests.get(url, headers=self.headers)
response.encoding = "utf-8"
# 注意下面两行代码在处理过程中容易多去花括号或者少去花括号,都会造成json格式报错,一定要注意
data = response.text.split('(', 1)[1] # 根据(进行切片一次处理,取第二部分
data = data[0:len(data) - 1] # 然后去掉后面的)和;
items = json.loads(data)
for i in range(len(items['data']['data'])):
item = items['data']['data'][i]['content']
# print(item)
self.info_list.append(item)
def write(self, info):
with open('comment.txt', 'a', encoding="utf-8") as f:
f.write(info + "\n")
f.close()
def main(self):
for page in range(1, 19):
if page == 1:
url = 'http://v.baidu.com/uc/comment/list?callback=jQuery111108169115031412963_1534155539196&page=1&workstype=movie&works_id=134804&_=1534155539197'
elif page < 3:
url = 'http://v.baidu.com/uc/comment/list?callback=jQuery111108169115031412963_1534155539180&page={}&workstype=movie&works_id=134804&_=153415553920{}'.format(
page, page + 6)
else:
url = 'http://v.baidu.com/uc/comment/list?callback=jQuery111108169115031412963_1534155539180&page={}&workstype=movie&works_id=134804&_=15341555392{}'.format(
page, page + 6)
self.get_page(url)
for info in self.info_list:
self.write(info)
self.ciyun()
if __name__ == "__main__":
aiqing = Aiqing()
aiqing.main()
|
这里还有要说的就是,上面的我们找的list那个文件,只是一页的评论数据,第二页要点击。加载更多,然后会出现后面的list文件,但是会发现,第一个跟后面的url不一样,也没有什么规律,所以我加了一个判断, 至于第2也到第4为什么也有,那是因为我没看到好的表示page的办法,所有就这样写了,大家有什么好办法也可以提出来。
利用数据制作词云
制作词云我们先找一个图片,用作词云的外形,然后就是代码了,我么写的是类,可能没必要,但是大家还是要养成一个好的习惯,而且感觉写类方法,很简单明了,我直接加两个词云方法就行了,也不会影响其他代码。直接上代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| def word_cloud(self, text):
words_list = []
word_generator = jieba.cut(text, cut_all=False) # 返回的是一个迭代器
for word in word_generator:
if len(word) > 1: # 去掉单字
words_list.append(word)
return ' '.join(words_list)
def ciyun(self):
back_color = imread('fengche.png') # 解析该图片
wc = WordCloud(
background_color='white', # 背景颜色
max_words=500, # 最大词数
mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略
max_font_size=50, # 显示字体的最大值
font_path="C:\Windows\Fonts\ygyxsziti2.0.ttf", # 找到本地字体文件,或者下载字体文件
random_state=10, # 为每个词返回一个PIL颜色
scale=15, # 默认值1。值越大,图像密度越大越清晰
# width=1000, # 图片的宽
# height=860 # 图片的长
)
# 打开保存的评论数据
text = open('comment.txt', encoding="utf-8").read()
text = self.word_cloud(text)
wc.generate(text)
# 基于彩色图像生成相应彩色
image_colors = ImageColorGenerator(back_color)
# 显示图片
plt.imshow(wc)
# 关闭坐标轴
plt.axis('off')
# 绘制词云
plt.figure()
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
# 保存图片
wc.to_file('apple.jpg')
print('comment.png has bee saved!')
|
这里大家需要安装两个库wordcloud、scipy和jieba安装方式直接(pip install 模块名),wordcloud是用来制作词云的,scipy.misc方法用来解析图片,jieba是用来切词的,我们需要将评论切分成词,我写的一个word_cloud()函数是用来切词的,WordCloud函数参数又很多,基本用到我的这些也就够了,我代码后面的注释也很详细,关于详细的如何设置,大家可以参看jieba+wordcloud,
这里有可能会存在编码格式的问题,大家如果在写入文件的时候设置的编码格式是utf-8的话,那么在写词云打开这个文本的时候也用utf-8编码,就不会存在编码格式的问题了,其他就没什么问题了,
这里写图片描述
我就随便弄了一个词云,大家可以找好看的图片,自己弄就行了。最后奉上全部代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
| # -*- conding=UTF-8 -*-
import requests
import json
import jieba
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
class Aiqing(object):
def __init__(self):
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
self.info_list = []
def get_page(self, url):
response = requests.get(url, headers=self.headers)
response.encoding = "utf-8"
# 注意下面两行代码在处理过程中容易多去花括号或者少去花括号,都会造成json格式报错,一定要注意
data = response.text.split('(', 1)[1] # 根据(进行切片一次处理,取第二部分
data = data[0:len(data) - 1] # 然后去掉后面的)和;
items = json.loads(data)
for i in range(len(items['data']['data'])):
item = items['data']['data'][i]['content']
# print(item)
self.info_list.append(item)
def write(self, info):
with open('comment.txt', 'a', encoding="utf-8") as f:
f.write(info + "\n")
f.close()
'''
绘制词云部分
'''
def word_cloud(self, text):
words_list = []
word_generator = jieba.cut(text, cut_all=False) # 返回的是一个迭代器
for word in word_generator:
if len(word) > 1: # 去掉单字
words_list.append(word)
return ' '.join(words_list)
def ciyun(self):
back_color = imread('fengche.png') # 解析该图片
wc = WordCloud(
background_color='white', # 背景颜色
max_words=500, # 最大词数
mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略
max_font_size=50, # 显示字体的最大值
font_path="C:\Windows\Fonts\ygyxsziti2.0.ttf", # 找到本地字体文件,或者下载字体文件
random_state=10, # 为每个词返回一个PIL颜色
scale=15, # 默认值1。值越大,图像密度越大越清晰
# width=1000, # 图片的宽
# height=860 # 图片的长
)
# 打开保存的评论数据
text = open('comment.txt', encoding="utf-8").read()
text = self.word_cloud(text)
wc.generate(text)
# 基于彩色图像生成相应彩色
image_colors = ImageColorGenerator(back_color)
# 显示图片
plt.imshow(wc)
# 关闭坐标轴
plt.axis('off')
# 绘制词云
plt.figure()
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
# 保存图片
wc.to_file('apple.jpg')
print('comment.png has bee saved!')
def main(self):
for page in range(1, 19):
if page == 1:
url = 'http://v.baidu.com/uc/comment/list?callback=jQuery111108169115031412963_1534155539196&page=1&workstype=movie&works_id=134804&_=1534155539197'
elif page < 3:
url = 'http://v.baidu.com/uc/comment/list?callback=jQuery111108169115031412963_1534155539180&page={}&workstype=movie&works_id=134804&_=153415553920{}'.format(
page, page + 6)
else:
url = 'http://v.baidu.com/uc/comment/list?callback=jQuery111108169115031412963_1534155539180&page={}&workstype=movie&works_id=134804&_=15341555392{}'.format(
page, page + 6)
self.get_page(url)
for info in self.info_list:
self.write(info)
self.ciyun()
if __name__ == "__main__":
aiqing = Aiqing()
aiqing.main()
|
谢谢!